IV. El conversor texto-voz
El conversor texto-voz (CTV) multilingüe
se realizó a partir de la estructura del conversor en español. En esta estructura,
se distinguen dos grandes bloques funcionales:
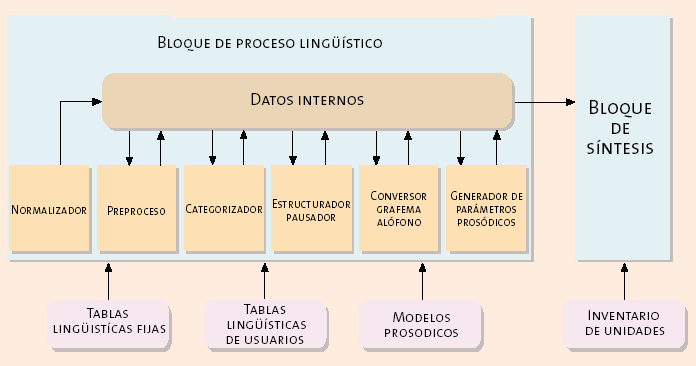
1. El bloque de proceso lingüístico
Los objetivos principales del bloque
de proceso lingüístico consisten en obtener la cadena de alófonos (sonidos)
que hay que pronunciar, así como la información sobre cómo pronunciar esos sonidos
(la duración de cada uno y la entonación del discurso), a partir de un texto
de entrada dado. El bloque de proceso lingüístico se compone de los siguientes
módulos: normalizador, preproceso, categorizador, estructurador-pausador, conversor
grafema-alófono y generador de parámetros prosódicos.
2. El bloque de síntesis de voz
La síntesis de voz se realiza mediante
la concatenación de unas unidades acústicas que previamente han sido diseñadas
y grabadas, y que se encuentran recogidas en un inventario. La concatenación
debe realizarse de manera controlada para obtener el discurso deseado sin discontinuidades,
ajustándose a las duraciones y al contorno de la frecuencia fundamental (entonación),
obtenidos por el módulo generador de parámetros prosódicos.
Uno de los problemas de la lectura
de texto es que no es un proceso fácilmente divisible en tareas que se puedan
separar de manera secuencial en el tiempo. Por ejemplo, el género que debe tener
la expansión de un número no se puede determinar hasta que no se haya hecho
algún tipo de análisis sintáctico para determinar las relaciones de dependencia
entre las palabras del texto. Sin embargo, el módulo que realice este análisis
seguramente no podrá manejar la variedad de un texto arbitrario y necesita que
se haya realizado previamente un cierto preproceso, una de cuyas tareas típicas
es la expansión de abreviaturas y números. Sin embargo, las estructuras no secuenciales
son muy difíciles de realizar y aumentan la complejidad de un sistema ya de
por sí bastante complejo. Por ello, la mayoría de los sistemas de conversión
texto-voz adoptan una estructura secuencial, en el que las restricciones impuestas
por la secuencialidad se intentan suplir con un uso inteligente de
la información que comparten los distintos bloques y módulos componentes.
Una posible estructura del conversor
texto-voz es la que se presenta en la figura 5.
En los siguientes apartados se hace
un repaso más detallado de los módulos del CTV.
IV.1. El módulo normalizador
Su tarea principal consiste en detectar
y reunir un conjunto de caracteres en el texto de entrada. Este conjunto de
caracteres es el que compondrá la mayor unidad de trabajo (y de información)
común al resto de los módulos del proceso lingüístico. Esta unidad de trabajo
es lo que normalmente coincide con una frase, aunque no en un sentido lingüísticamente
exacto.
También realiza otra serie de tareas
complementarias, como es detectar la forma (todo en minúsculas, con inicial
mayúscula, etc.) en la que aparecen escritas las palabras (todo aquello que
aparezca entre blancos), resolver algunas ambigüedades en la interpretación
de los signos ortográficos, y hacer una primera y muy somera clasificación de
las palabras (se compone sólo de letras, se compone sólo de dígitos, etc.).
La tarea de detectar las frases en el texto de entrada presenta
numerosas ambigüedades y dificultades, pues no siempre se puede decir que un
signo ortográfico determinado marque el final de una frase. Quizás el caso más
complejo que se presenta es el del punto. Desde luego, un punto puede indicar
fin de frase, pero también se emplea en otros muchos casos, como son las abreviaturas
("min."), los números ("10.423"), las iniciales de nombres
("J.L. Serrano"), etc. Distinguir estos
casos no es siempre fácil. La solución adoptada ha sido permitir que el normalizador
sólo detecte el final de frase en los casos más claros, y que deje pasar los
casos más ambiguos. Por tanto, en ocasiones, la frase detectada por el normalizador
contendrá, en realidad, más de una frase. El preproceso, que hace un análisis
más detallado de cada palabra, será el encargado de decidir después si los posibles
finales de frase intermedios lo son o no.
IV.2. El módulo de preproceso
Se encarga de expandir y modificar
las palabras que recibe a su entrada, de manera que a su salida todo, excepto
los signos ortográficos, haya sido reducido a palabras completamente alfabéticas
que puedan ser procesadas por el resto de los módulos. Para reducir la variabilidad
del texto de entrada, es necesario que el preproceso expanda en forma alfabética
todo aquello que no se lee directamente tal y como aparece representado (cantidades
numéricas, abreviaturas, representaciones de fechas, etc.). También se reduce
la variabilidad de la escritura, pasando todo a letras minúsculas.
Una vez que todas las palabras ya
se encuentran en forma alfabética, el preproceso realiza otra serie de tareas,
como son la división en sílabas y la acentuación fonética.
A continuación se describen las distintas
tareas del módulo de preproceso.
► La expansión de formas
Se trata de expandir en palabras los
números, abreviaturas, fechas, etc., que aparezcan en el texto. Esta tarea presenta
dos dificultades generales, que hemos encontrado en todos los idiomas:
1. Conflictos entre los formatos de
distintas expresiones. Por ejemplo, "C" puede ser un número romano,
una clase de vitamina o un grado de la administración pública. Hemos realizado
métodos heurísticos para aventurar el tipo de interpretación en función del
contexto. Sin embargo, estos métodos no son infalibles y hemos decidido permitir
que el usuario pueda decidir el tipo de interpretación, pues él sabe qué tipo
de textos va a leer el CTV. Para ello, ha sido necesario disponer mecanismos
por los que el usuario del sistema de conversión pueda decidir qué clases de
expresiones van a aparecer en el texto y cómo deben leerse.
2. Aunque se haya identificado correctamente
el tipo de expresión, a veces falta una norma o referencia que indique cómo
debe pronunciarse (por ejemplo, en la expansión de una fecha, ¿cuándo se utiliza
"de" y cuándo "del"?, o al tratar una sigla, ¿cuándo se
deletrea, cuándo se expande o cuándo se lee como una palabra cualquiera del
idioma?). Estas decisiones quedan al buen juicio del desarrollador, pero este
buen juicio no tiene porque ser bueno, de acuerdo al juicio del usuario del
sistema. Por eso, también en este sentido hemos intentado dar la máxima flexibilidad
al usuario.
Además de estas dificultades, centrándonos en el aspecto multilingüe,
aparecen otros problemas; en español, catalán, gallego y portugués es necesario
cuidar la concordancia en la expansión de los números y las abreviaturas. En
el caso de los números, éstos deben concordar con el sustantivo al que acompañan,
si existe, y las abreviaturas deben expandirse en singular o plural, en función
de las cantidades que las acompañen. Para realizar esta tarea de manera eficaz,
es necesario retrasar la decisión sobre el género de las expansiones de los
números hasta después de haber realizado la categorización, para así poder localizar
el sustantivo al que acompañan (si existe) e intentar aventurar su género.
►La silabicación
La silabicación
se utiliza, fundamentalmente, para decidir la acentuación fonética de las palabras,
para decidir en algunos casos sobre la conversión grafema-alófono y como ayuda
para deletrear secuencias de letras que se consideran impronunciables. Se ha
diseñado un sistema de reglas, que permite realizar esta tarea. Este procedimiento presenta
algunas limitaciones: no es capaz de recoger fácilmente criterios morfológicos
(para silabicar "transatlántico", por ejemplo), se basa en la secuencia
de letras y no de sonidos (por lo que si admitimos "[eksamen]"
como transcripción de "examen", no es posible
silabicar entre la oclusiva y la fricativa) y no tiene
en cuenta fenómenos de contacto entre palabras (si fueran pertinentes). A pesar
de estas limitaciones, el sistema es adecuado para las necesidades descritas
al principio y ha demostrado ser lo bastante flexible para ser aplicado en todos
los idiomas, sin demasiado esfuerzo.
►La acentuación
Esta tarea determina si la palabra
que se está tratando es átona o tónica y, en este último caso, sobre qué vocal
recae el acento. Pueden aparecer formas cuya acentuación depende de la categoría
gramatical de la palabra (por ejemplo, "sobre" puede ser tónica o
átona). También se identifican
estos casos, en los que hay que esperar a que se haya realizado la categorización
para poder deshacer la ambigüedad. Para realizar esta tarea, los idiomas español,
catalán, gallego y portugués responden a un conjunto de reglas bastante bien
definidas. Supuesta una silabicación correcta (para
este propósito), la acentuación no presenta ningún problema. Aunque conceptualmente
es un problema distinto, más propio del módulo conversor grafema-alófono, se
ha decidido asociar la determinación del timbre de las vocales al acento, por
razones prácticas.
IV.3. El módulo categorizador
La tarea principal de este módulo
consiste en asignar a cada palabra una categoría gramatical. La información
de la categoría gramatical se utiliza fundamentalmente para decidir sobre la
inserción de pausas y su caracterización. Además, las categorías se emplean
para la corrección del acento, en la determinación del género, en la expansión
de los números y en la transcripción grafema-alófono.
Esta tarea se compone de dos fases:
En la primera se decide la categoría de la palabra a
partir de su forma, basándose en listas de excepciones, de terminaciones y de
raíces. Para esta fase, se han desarrollado herramientas que, a partir de un
diccionario, conjugan los verbos y generan las formas flexionadas. A continuación,
se eligen automáticamente listas de terminaciones, y excepciones a esas terminaciones,
que de manera óptima permiten la clasificación de las palabras (dentro de las
limitaciones de memoria del entorno de funcionamiento del CTV).
En la segunda fase se resuelven las ambigüedades mediante
reglas que tienen en cuenta el contexto en el que aparece la palabra (reglas
de contexto). Al final de este módulo, con el mismo mecanismo de reglas de contexto,
se realiza la corrección del acento que quedó pendiente en el módulo de preproceso.
IV.4. El módulo estructurador-pausador
La tarea principal de este módulo
consiste en la localización de pausas no marcadas ortográficamente. Además,
se caracterizan las pausas ortográficas y no ortográficas. Esta caracterización
determina no sólo la duración de las pausas, sino también la evolución del contorno
de la entonación.
Las pausas no marcadas ortográficamente
se introducen cuando se detecta que no es posible (o natural) leer un fragmento
de texto demasiado largo sin hacer ninguna pausa intermedia. Para la selección
de puntos donde realizar pausas no marcadas ortográficamente se utiliza el mismo
mecanismo de reglas de contexto del que se ha hablado anteriormente. Con estas
reglas se forman grupos de palabras, entre los que no está permitido realizar
pausas (semejantes a sintagmas de una estructura sintáctica plana), y posteriormente
se asigna un peso o probabilidad de realizar una pausa a cada límite entre dos
sintagmas. A continuación se elige el mejor punto para realizar la pausa, basándose
en los pesos asignados y en criterios rítmicos. De momento, estos criterios
son independientes del idioma (es decir, se han tomado los que se venían utilizando
en español), si bien han demostrado un buen funcionamiento en todos los idiomas
tratados hasta el momento.
Finalmente, se caracterizan las pausas,
tanto las ortográficas como las introducidas por este módulo. Para esta caracterización
se utiliza un conjunto de tipos de pausas posibles.
IV.5. El módulo conversor grafema-alófono
Su función es obtener la secuencia de sonidos (alófonos) correspondiente
a la secuencia de letras de una frase dada. Para ello, se sirve de informaciones
de distinto tipo, obtenidas en los módulos anteriores. Lo primero que hubo que
hacer para el CTV multilingüe, fue diseñar un conjunto de alófonos que cubriera
las necesidades de todos los idiomas considerados. Se amplió el conjunto de
alófonos del CTV español, al que se incorporaron todos los alófonos adicionales
necesarios.
Se empleó un procedimiento de reglas
para realizar la transcripción fonética. Cada idioma
cuenta con unos ficheros de reglas propios, que son parte de las tablas que
hay que cargar y seleccionar para que el CTV funcione en un idioma determinado.
La transcripción se hace partiendo de los caracteres
silabicados y acentuados fonéticamente de las palabras de
una frase. La acentuación fonética también indica el timbre adecuado de las
vocales en los idiomas catalán, gallego y portugués.
Sobre todo en el caso del catalán,
aparecen diversos procesos fonológicos de asimilación que dificultan la realización
de la transcripción fonética de una manera secuencial,
desde el principio hasta el final de la frase. Para solucionar este problema
se ha dividido el proceso de transcripción fonética
en dos fases:
1. La primera trabaja recorriendo
los caracteres silabicados, y acentuados fonéticamente,
desde el principio hasta el final de la frase. En aquellos casos en que no se
puede decidir el alófono concreto, equivalente a un carácter (o caracteres),
porque depende de alguna característica del alófono siguiente (que todavía no
ha sido obtenido), se genera temporalmente un alófono que recoge la ambigüedad
encontrada.
2. La segunda recorre los resultados
de la primera fase en orden inverso (desde el final hasta el principio) y va
resolviendo las ambigüedades que quedaron pendientes.
Uno de los problemas que queda pendiente
de resolver es el caso de las transcripciones fonéticas "forzadas".
Por ejemplo, cuando nos encontramos con una palabra que en algunas ocasiones
hay que pronunciar de acuerdo a las reglas de un idioma, y que en otras hay
que pronunciar de acuerdo a las reglas de otro idioma distinto. Este es un caso
relativamente frecuente con los nombres y apellidos de personas. De momento,
la transcripción fonética siempre se hace de acuerdo a las reglas
del idioma seleccionado en el CTV multilingüe.
IV.6. El módulo generador de parámetros
prosódicos
Una vez obtenida la secuencia de alófonos,
es necesario añadirles más información para determinar la manera en que deben
ser pronunciados o entonados. La tarea de este módulo consiste en asignar duración
a cada uno de los alófonos generados en el módulo de conversión grafema-alófono
(incluidas las pausas) y un contorno entonativo a
cada grupo fónico. La naturalidad al hablar se consigue con una buena entonación,
la cual puede ser incluso necesaria en algunos casos para la inteligibilidad
del mensaje. Por ejemplo, la frase "Él dijo su amigo es un mentiroso",
se puede pronunciar de forma diferente, de manera que se podría interpretar
de cualquiera de los siguientes modos: "Él dijo: su amigo es un mentiroso",
o "Él, dijo su amigo, es un mentiroso". En este caso, la entonación
contribuye a que cambie el significado del mensaje. Por esto, la entonación
se considera uno de los principales responsables de la calidad de un conversor
texto-voz.
La entonación se
considera, físicamente hablando, como una combinación lineal de 3 parámetros:
frecuencia fundamental, duración y amplitud, y según varíen estos parámetros,
la entonación será diferente.
El modelo de
duraciones es un modelo multiplicativo, el cual calcula la duración de cada
sonido a partir de una duración base, que se modifica en función de distintos
factores dependientes del contexto (naturaleza de los sonidos adyacentes, acentuación
o no acentuación, proximidad al fin o al inicio del grupo fónico, etc.).
El modelo de entonación asigna un
contorno entonativo a cada grupo fónico, extraído
de una base de datos de contornos patrón, caracterizados en función del número
de sílabas tónicas del grupo, del tipo de pausa que lo finaliza, y de si acaba
en sílaba tónica o átona. Se busca el contorno más adecuado al grupo fónico
que se está tratando en cada momento y, en el caso de que no se pueda encontrar
un contorno apropiado, se construye uno, concatenando modelos de fragmentos
correspondientes a tres zonas del grupo fónico: inicial (hasta la primera sílaba
tónica), central y final (desde la última sílaba tónica hasta el final).
Para poder ajustar los parámetros
de los modelos de duración y de entonación, es necesario disponer de un banco
de datos de voz con información prosódica. Este banco de datos se obtiene seleccionando
un conjunto de textos, que cubran todos los factores de los modelos (así como
otros factores no contemplados que se deseen validar), y grabando a un locutor.
A continuación se añade información prosódica (se segmentan los sonidos, se
calculan los contornos entonativos, y se enriquece
el texto con información de acentos y pausas) y se generan los parámetros de
los modelos de duración y de entonación por métodos estadísticos.
El empleo de bancos de datos de voz,
junto con la automatización parcial del proceso de obtención de los modelos
de prosodia, permitirán personalizar la caracterización
prosódica de la voz sintética del conversor, tanto para los nuevos idiomas que
se añadan, como para las nuevas voces sintéticas (locutores) que se quieran
desarrollar para un idioma ya incorporado en el CTV.
IV.7. El bloque de síntesis
El bloque de síntesis de voz no se
subdivide en módulos. Su tarea es generar la voz sintética a partir de la información
de alófonos y prosodia, así como la correspondiente al inventario de unidades.
Este módulo es totalmente independiente del idioma. Maneja el conjunto de alófonos
común a todos los idiomas, y la particularidad de cada uno queda recogida en
su inventario de unidades, una tabla que, como todas las tablas propias de un
idioma, se puede cargar, así como descargar y sustituir por otra, de manera
dinámica.
Los parámetros acústicos (dependientes
del modelo de síntesis empleado) de cada alófono quedan recogidos en el inventario.
Sin embargo, la caracterización sonoro/sordo del alófono y su tratamiento por
el modelo de síntesis (en el caso del modelo LPC) se hace por código. Así, mientras
que en español sólo se tienen alófonos sonoros o sordos, al incluir el catalán
aparecen sonidos fricativos sonoros, que precisan una caracterización mixta
en el modelo de síntesis LPC.
Por otra parte, las peculiaridades
del conjunto de alófonos de cada idioma es un factor que hemos de tener en cuenta,
aunque haya quedado recogido en una tabla ajena al código. Al aumentar el número
de alófonos, y sobre todo el número de vocales (se consideran 5 vocales en español
y euskera, 7 en gallego, 8 en catalán y 14 en portugués),
aumenta de manera importante el tamaño de dicha tabla. Puesto que el sistema
tiene que funcionar con unos recursos limitados de memoria, esta característica
puede repercutir en una merma de la calidad acústica de los inventarios con
mayor número de alófonos, al ser necesario restringir las combinaciones recogidas,
o bien aplicar una codificación más fuerte para reducir el tamaño final del
inventario.
El procedimiento que se usa de forma
más común para generar la voz sintética en los sistemas de conversión texto-voz
consiste en la concatenación controlada de unidades acústicas, previamente extraídas
de grabaciones realizadas por una persona. Estas unidades deben ser modificadas
en su duración y entonación para que se ajusten a la prosodia sintética generada
por el conversor texto-voz cuando tiene que pronunciar una frase.
Este tipo de técnica de síntesis produce
actualmente una voz con una inteligibilidad y naturalidad superior a otras,
pero tiene que contar con procedimientos para solucionar los problemas derivados
de la concatenación de unidades acústicas que han sido grabadas en diferentes
ficheros de voz y en diferentes instantes de tiempo, y que tienen características
acústicas distintas.
La concatenación de unidades acústicas
nos ayuda a solucionar un problema muy difícil de modelar, como es el caso de
preservar la forma en que las personas realizan cada uno de los sonidos y las
transiciones entre ellos; pero también nos introduce un problema importante:
¿cómo concatenar fragmentos de señales de voz que son bastante distintos a ambos
lados de un punto de concatenación? Fundamentalmente, al concatenar se producen
dos tipos de discontinuidades:
1. Diferencias en el espectro de
amplitud (caída espectral, frecuencia y ancho de banda de los formantes).
Este tipo de diferencias se percibe claramente como un cambio brusco en el timbre
del sonido.
2. Errores de sincronización de
los sonidos sonoros. Cuando hay diferencias en las componentes lineales
del espectro de fase, se produce un desalineamiento
entre uno o más periodos de la señal, que rompe la periodicidad propia de los
sonidos sonoros. Este tipo de errores se percibe como sonidos "poco limpios",
con "golpes" y con alteraciones en la entonación (rápidas y bruscas
subidas o bajadas de la frecuencia fundamental). Este tipo de discontinuidad
se puede denominar "incoherencia entre tramas". En los sonidos sordos
(que no tienen una forma de onda periódica), la "incoherencia entre tramas"
no es importante perceptualmente.
Para aliviar el primer tipo de discontinuidades,
la solución que se adopta más comúnmente consiste en realizar una interpolación
de las envolventes espectrales. Una simple interpolación lineal basta para hacer
que las discontinuidades de la caída espectral y de los formantes sean menos
perceptibles (si bien, el problema no se soluciona completamente, sobre todo
cuando hay diferencias muy importantes a la izquierda y a la derecha del punto
de concatenación).
El segundo tipo de discontinuidades
es más difícil de resolver. Hasta el momento, se han empleado dos procedimientos
diferentes para eliminar el problema de los "desalineamientos de fase" al hacer la concatenación de
las unidades acústicas. Estos son:
1. Hacer un marcado de los instantes
de cierre de la glotis en las unidades acústicas. Estos instantes (normalmente
llamados "epochs" u "onsets") indican un punto en cada periodo de los
sonidos sonoros, que se relaciona de forma síncrona
(armónica) con los periodos adyacentes, de los cuales está separado por la duración
del periodo fundamental (el inverso de la frecuencia fundamental, que coincide
con la frecuencia de vibración de las cuerdas vocales). Al marcar los instantes
se puede hacer que las ventanas de análisis de las unidades acústicas estén
centradas en estos puntos, además se sabe que al combinar las tramas acústicas
durante la síntesis, todas ellas estarán centradas en puntos relacionados armónicamente
con la trama anterior y con la trama siguiente, evitándose así los desalineamientos
de fase. El problema es que la tarea de marcado de los "onset"
es un proceso que lleva mucho tiempo, porque precisa de un cuidadoso repaso
manual.
2. Sustituir la fase original de
la señal, suponiendo que ésta es de fase mínima. Cuando se supone que una
trama de voz es de fase mínima, la fase de la señal está determinada por el
espectro de amplitud de dicha señal. Esto equivale a desplazar cada una de las
tramas de análisis, haciendo que la forma de onda de la señal aparezca con uno
de sus periodos centrados en la trama de análisis. La principal virtud de este
procedimiento es que nos permite eliminar el problema de la sincronización entre
tramas sucesivas sin necesidad de hacer un marcado de los "onset". El inconveniente que tiene es que aunque
la hipótesis de fase mínima es bastante aproximada para muchos locutores y para
la mayoría de los sonidos, hay ciertos locutores y
cierto tipo de sonidos (por ejemplo, los sonidos nasales) en los que la hipótesis
de fase mínima no es adecuada e introduce alguna distorsión.
La estrategia que se ha
decidido utilizar para obtener un modelo de síntesis de mayor calidad ha sido
emplear un modelo sinusoidal que tenga en cuenta
la fase verdadera de la señal de voz, puesto que la hipótesis de
fase mínima no permite respetar la forma de onda de los periodos de la señal
de voz original, aunque sí su contenido en frecuencia.
Dado que la hipótesis
de fase mínima introduce distorsión en la señal de voz, incluso en el caso de
no pegar trozos procedentes de distintas grabaciones, se ha podido comprobar,
en experimentos de análisis y resíntesis (es decir,
sin pegar trozos de distintas grabaciones), que el modelo sinusoidal con fase
es capaz de reflejar más fielmente las características de la grabación original
que el modelo de fase mínima.
El problema de los desalineamientos de fase se está tratando como una cuestión
de sincronización de señales de voz. Es decir, se pretende obtener un punto
de cada trama de análisis de voz que permita "realinear" o "desplazar"
dichas tramas, de manera que cualquier trama de cualquier fichero de voz esté
centrada en un punto de características semejantes. Esto permite construir una
secuencia de tramas sin problemas
de sincronismo.
Basándonos en la propiedad
de la transformada de Fourier, de que un desplazamiento
en el dominio del tiempo equivale a añadir una componente lineal al espectro
de fase de la señal original, y usando las propiedades del centro de gravedad
de las señales, se puede modificar el espectro de fase de la señal original,
de manera que la señal resultante sea igual a la señal original, con su centro
de gravedad desplazado al centro de la trama de análisis. De esta manera se
pueden sincronizar todas las tramas de análisis.
Hasta el momento, las
pruebas hechas con el modelo sinusoidal con fase han presentado resultados muy
prometedores, si bien quedan por mejorar algunos aspectos, como son la robustez
de los puntos de sincronización, la necesidad de reducir la memoria ocupada
para almacenar la información del espectro de amplitud y fase de las tramas,
y el uso de unos parámetros adecuados que permitan, por un lado, hacer una adecuada
interpolación de la información espectral y, por otro, reducir el tiempo necesario
para hacer la síntesis de voz.
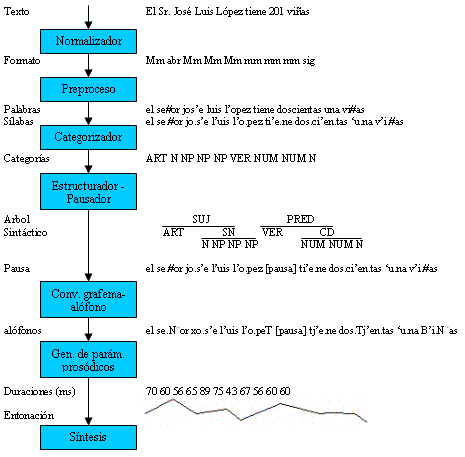
Un ejemplo del proceso llevado a cabo
con un texto, en concreto la frase José Luis López tiene 201 viñas, hasta
convertirlo en voz se puede observar en la figura 6.
IV.8. Aplicaciones del conversor
texto-voz
Un conversor texto-voz se emplea en
cualquier situación en la que sea necesario presentar información de forma hablada,
cuando esa información sólo se encuentra disponible en forma escrita, bien directamente
o bien porque se puede convertir fácilmente a texto (por ejemplo, los campos
de información que se encuentran en una base de datos).
Un ejemplo destacable del uso de los
conversores texto-voz es como alternativa o complemento a la presentación visual
de la información en la pantalla de un ordenador. Piénsese en el caso de los
invidentes o deficientes visuales que, de esta forma, pueden tener un medio
que constituye una gran ayuda para manejar unas herramientas, tan importantes
hoy en día, como son los ordenadores. Así se puede contribuir a mejorar la integración
laboral de estas personas, y facilitar su acceso a la información (lectura de
periódicos, libros, páginas web, etc.).
Otro ámbito de interés en el que se
pueden usar los conversores texto-voz es el caso de un usuario que desea poder
acceder a una información desde cualquier sitio y en cualquier instante, sin
necesidad de disponer de un ordenador conectado a la red, y sin tener en cuenta
si en ese momento hay disponible un operador humano que pueda darle esa información
(por no estar en el horario de atención al público, o por no contar con un número
suficiente de operadores y estar todos ocupados). En este caso, la solución
más directa es poder acceder a esa información desde un teléfono convencional,
llamando a un sistema automático que le proporcione esa información. La ventaja
de este procedimiento es que prácticamente desde cualquier sitio se puede hacer
una llamada telefónica, especialmente teniendo en cuenta la amplia difusión
que han alcanzado los teléfonos móviles. La llamada telefónica se dirige a un
ordenador especializado (servidor vocal) que puede acceder a la información
deseada, pasarla a forma de texto (si es que originalmente no se encontraba
ya en esa forma), y proporcionar esa información al usuario, convertida previamente
en voz por un conversor texto-voz. Algunos ejemplos de este uso de los conversores
texto-voz son las consultas de información bancaria (saldos y movimientos de
una cuenta), la información de consumo de un suministro (llamadas telefónicas,
gas...), los servicios de noticias, la información administrativa (servicios,
estado de la tramitación de una solicitud...) y la información de espectáculos
(cines, teatros, televisión...).