5.La psicoacústica en la codificación
Cualquier dispositivo que produzca sonido con el propósito del disfrute humano debería tomar en cuenta lo que los oídos harán con ese sonido. Algunos de estos imperativos de diseño son mucho más que sentido común, y tampoco pueden ser analizados satisfactoria y completamente a través de una prueba de escucha casual. En muchos casos se requiere un conocimiento más profundo y real del problema.
La audición humana es un proceso extraordinariamente complejo, que apenas está comenzando cuando el sonido golpea el tímpano y es convertido de variaciones en la presión del aire a impulsos nerviosos. De ahí en adelante, es asunto de la mente, y la psicología se convierte en factor importante para estudiar y analizar los sonidos, así como las reacciones de las personas ante éstos.
Por ejemplo, ¿Cómo diseñar un dispositivo de compresión de datos que reduzca la cantidad de información digital viajando por una línea telefónica sin afectar la calidad del sonido percibido? ¿Cómo se determina un nivel seguro o confortable de exposición al ruido en una fábrica? ¿Cómo diseñar un sistema de advertencia auditivo que sea claramente audible sobre el ruido de fondo sin ser causa de distracción? Un buen conocimiento en psicoacústica puede ser de gran ayuda en todos estos problemas de diseño.
ASPECTOS RELEVANTES
En concreto, hay cuatro aspectos que son los m´s interesantes y útiles para el desarrollo de un codificador MP3. Son los que se mencionan a continuación.
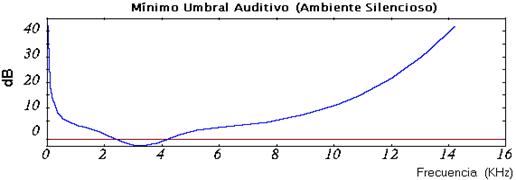
1. Mínimo umbral auditivo
Este umbral, también conocido como umbral absoluto, corresponde al sonido de intensidad más débil que se puede escuchar en un ambiente silencioso. El mínimo umbral auditivo no tiene un comportamiento lineal; se representa por una curva de Intensidad (dB) contra Frecuencia (Hz), que posee niveles mínimos entre 2 y 5 KHz, los cuales corresponden a la parte más sensitiva del oído humano. Por lo tanto, en los sistemas de compresión de audio que sacan provecho de la psicoacústica, no es necesario codificar los sonidos situados bajo este umbral (el área por debajo de la curva), ya que éstos no serán percibidos.
2. Enmascaramiento.
El efecto de enmascaramiento
se basa en las limitantes del oído humano para responder a todas las componentes
de un sonido complejo. Durante los sonidos fuertes, no se pueden oír los sonidos
más débiles. Por ejemplo, cuando un músico organista no está tocando, se puede
escuchar el resoplido de los tubos; y cuando el músico toca, se pierde el sonido
de éstos porque ha sido enmascarado. Es el ejemplo más fácil de entender
de enmascaramiento, pero hay más:
2.1. Enmascaramiento en frecuencia.
Funciona de manera que un sonido en determinada frecuencia puede enmascarar o disminuir el nivel de otro sonido en las frecuencias adyacentes, siempre y cuando el nivel del sonido enmascarante sea más alto (un sonido más intenso, más fuerte) que el nivel del sonido adyacente.

2.2. Enmascaramiento temporal.
Se presenta cuando un tono suave está muy cercano en el dominio del tiempo (unos cuantos milisegundos) a un tono fuerte. Si se está escuchando un tono suave y aparece un tono fuerte, el tono suave será enmascarado por el tono fuerte, antes de que el tono fuerte efectivamente aparezca (preenmascaramiento). Posteriormente, cuando el tono fuerte desaparece, el oído necesita un pequeño intervalo de tiempo (entre 50 y 300 ms) para que se pueda seguir escuchando el tono suave (postenmascaramiento).
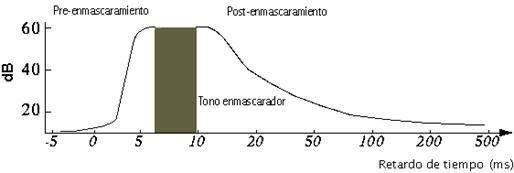
Con el postenmascaramiento no hay problemas; pero el preenmascaramiento sugiere
que un tono será enmascarado por otro tono, antes de que el tono enmascarador
realmente aparezca, atentando contra el buen juicio de cualquier oyente. Para
este fenómeno, se han presentado dos explicaciones:
1) El cerebro integra el sonido sobre un período de tiempo, y procesa la información por ráfagas en la corteza auditiva
2) Simplemente, el cerebro procesa los sonidos fuertes más rápido que los sonidos suaves.
Sin importar el mecanismo,
el caso es que el preenmascaramiento temporal en verdad existe, así sea
exageradamente pequeño (se ha calculado con un valor aproximado de 30 ms).
En un sonido cualquiera, se presentan ambos tipos de enmascaramiento. El
enmascaramiento en frecuencia es mucho más importante que el enmascaramiento
temporal; aunque en ciertos dispositivos para compresión de audio se tienen en
cuenta ambos tipos de enmascaramiento, con lo cual se logra mejor compresión de
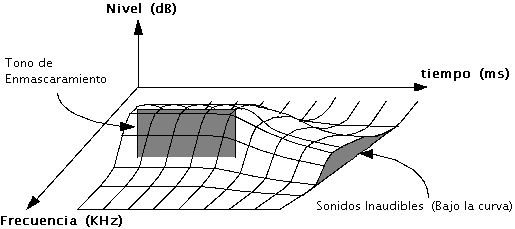
datos. Superponiendo ambas gráficas en una sola que presente tres ejes, se puede
ver una curva bajo la cual están todos los sonidos que no pueden ser escuchados.
3. Joint stereo o estéreo conjunto.
Si una señal de audio es estereofónica se puede lograr comprimirla, con base en la irrelevancia o redundancia entre ambos canales. Por ejemplo, en muchas locaciones de alta fidelidad, existe un único y potente altavoz denominado "BOOMER". Sin embargo, se tiene la impresión de que el sonido proviene de diferentes fuentes como si existieran parlantes en todas las direcciones. En la realidad, por debajo de una frecuencia determinada, el oído ya no es capaz de localizar el origen espacial de los sonidos. De esta manera, algunas frecuencias se pueden grabar como señal monofónica seguida por un pequeño código para lograr restaurar un pequeño porcentaje de espacialización en la decodificación.
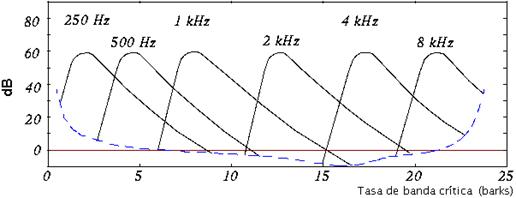
4. Las bandas críticas y el bark.
4.1. Bandas críticas.
Estudios de la discriminación en frecuencia del oído han demostrado que en las bajas frecuencias, tonos con unos cuantos Hertz de separación pueden ser distinguidos; sin embargo, en las altas frecuencias para poder discriminar los tonos se necesita que estén separados por cientos de Hertz. En cualquier caso, el oído responde al estimulo más fuerte que se presente en sus diferentes regiones de frecuencia; a este comportamiento se le da el nombre de bandas críticas. Los estudios muestran que las bandas críticas son mucho más estrechas en las bajas frecuencias que en las altas; el 75% de las bandas críticas están por debajo de los 5 KHz, lo que implica que el oído recibe más información en las bajas que en las altas frecuencias. Las bandas críticas tienen un ancho de aproximadamente 100 Hz para las frecuencias de 20 a 400 Hz; este ancho aumenta de manera logarítmica a medida que aumenta la frecuencia. Se ha comprobado que el ancho de las bandas críticas se puede aproximar con la fórmula:
Ancho de la banda crítica (Hz) = 24.7 (4.37F + 1)
F es la frecuencia central en KHz.
Las bandas críticas son comparables a un analizador de espectro con frecuencia
central variable. Más importante aún es el hecho de que las bandas críticas no
son fijas; son continuamente variables en frecuencia y cualquier tono audible
creará una banda crítica centrada en él. Mirado desde otro punto de vista, el
concepto de la banda crítica es un fenómeno empírico: una banda crítica es el
ancho de banda al cual las respuestas subjetivas cambian abruptamente.
4.2. El bark.
El bark (en honor al físico alemán Georg Heinrich Barkhausen) es la unidad de frecuencia perceptual; específicamente, un bark mide la tasa de banda crítica, o sea, una banda crítica tiene un ancho de un bark. La escala bark relaciona la frecuencia absoluta (en Hz) con las frecuencias medidas perceptualmente (el caso de las bandas críticas). Usando el bark, un sonido en el dominio de la frecuencia puede ser convertido a sonido en el dominio psicoacústico. De esta manera, un tono puro (representado por una componente en el dominio de la frecuencia) puede ser representado como una curva de enmascaramiento psicoacústico. Eberhard Zwicker modeló el oído con 24 bandas críticas arbitrarias para frecuencias por debajo de 15 KHz, con una banda adicional que ocupa la región entre 15 y 20 KHz. El bark (ancho de una banda crítica) puede calcularse con las siguientes fórmulas:
![]()
f = frecuencia.
Nota: Para determinar el ancho de una banda crítica, se pueden
usar estas fórmulas o la fórmula mostrada anteriormente (en la cláusula 4.1).
De las consideraciones anteriores, se deduce que el umbral de enmascaramiento es
diferente cuando se tienen en cuenta las bandas críticas. El umbral sin tener en
cuenta las bandas críticas, sería:
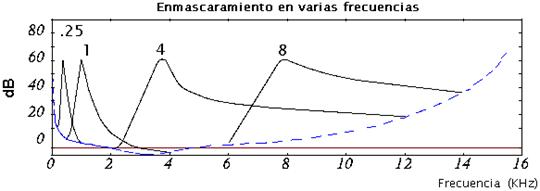
Y teniendo en cuenta las bandas críticas:
CONCLUSIÓN
Por lo tanto, con lo que se ha mostrado acerca de la psicoacústica, se concluye que no todos los sonidos tienen la misma relevancia. Estas propiedades son usadas por los mecanismos de compresión de audio (MP3, etc.) para disminuir la cantidad de datos necesarios para representar un sonido, basándose en un modelo psicoacústico que simula el comportamiento del oído humano. Se toma ventaja de las limitaciones del oído (así como del cerebro) para responder a todas las componentes en una onda de audio compleja y, de esta manera, lograr que los mecanismos de compresión calculen lo que se oirá de un sonido particular, descartando el material indetectable o codificándolo con menos precisión, idealmente sin cambiar la calidad del sonido percibido.