|
GRABACION DE AUDIO |
|
|
GRABACION DE AUDIO |
|
Bases del audio digital:
Antes de que la computadora pueda grabar, manipular y reproducir sonido, debe transformarse el sonido de una forma analógica audible a una forma digital aceptable por la computadora, mediante un proceso denominado conversión analógica - digital (ADC). Una vez que los datos de sonido se han almacenado como bytes en la computadora, puede hacerse uso de la potencia de la CPU de la computadora para transformar este sonido de miles de modos. Finalmente, cuando se está dispuesto a escuchar el resultado, el proceso de conversión digital-analógica (DAC) transforma de nuevo los bytes de sonido a una señal eléctrica analógica que emiten los altavoces.
Muestreo: Conversión analógica-digital
Dada una señal analógica, se van tomando valores discretos de su amplitud a intervalos de tiempo pequeños, evidentemente será más fiable la reproducción cuantas más muestras por segundo se tomen. A estos valores obtenidos se les asigna un valor digital que el computador puede entender y procesar como se requiera. Podemos utilizar palabras de 8 o 16 bits pudiendo obtener así 256 ó 65536 combinaciones distintas y obtener mayor resolución.

FRECUENCIA DE MUESTRA: Según el teorema de Nyquist, es posible repetir con exactitud una forma de onda si la frecuencia de muestreo es como mínimo el doble de la frecuencia de la componente de mayor frecuencia. La frecuencia más alta que puede percibir el oído humano está cercana a los 20 kHz, de modo que la frecuencia de muestreo de 44.1 kHz de las tarjetas de sonido es más que suficiente. Este valor es el utilizado hoy en día por los reproductores de audio CD.
TAMAÑO DE MUESTRA: El tamaño de muestra controla el rango dinámico que puede grabarse. Por ejemplo, las muestras de 8 bits limitan el rango dinámico a 256 pasos (rango de 50 dB). Por el contrario, una muestra de 16 bits tiene un rango dinámico de 65.536 pasos (rango de 90 dB) una mejora sustancial. El oído humano percibe todo un mundo de diferencias entre estos dos tamaños de muestra. Los oídos son más sensibles a la detección de diferencias en el tono que en la intensidad, pero son aún más sensibles a la fuerza del sonido.
A partir de los anteriores procesos podemos conseguir un archivo de audio, como por ejemplo (y ya que es el más conocido), un archivo de audio WAV. Es el formato propio de Windows. Pueden ser de 8 o 16 bits con indices de muestreo de 11,025 kHz, 22,05 kHz o 44,1 kHz y por lo general tienen buena calidad de sonido.
Compresión de audio digital
Se podría asumir que todo lo que hay que hacer para obtener buen sonido es grabar a la velocidad límite de 44,1 kHz con muestras de 16 bits (2 bytes). El único problema que aparece si se graba en estéreo, tomando muestras simultáneamente en los canales izquierdo y derecho a 44,1 kHz, una muestra de sonido de un minuto necesita un espacio para almacenarse de 10,58MB. Esto conlleva emplear grandes espacios de disco para almacenar estos ficheros de sonido. Se han desarrollado muchos formatos de archivos comprimidos (códecs) que permiten realizar grabaciones de alta calidad sin necesidad de utilizar tanto espacio de disco.
Formatos de audio más comunes:
Con el simple objetivo de enumerar una serie de códecs utilizados por distintos sistemas operativos para realizar la compresión de audio. Posteriormente se realiza una descripción más completa del más utilizado: el MP3.
Por tanto, algunos de los más utilizados son:
Advanced Audio Coding (AAC): utilizado por los ordenadores Apple. Más eficiente que MP3.
Audio for Unix (AU): estándar acústico para el lenguaje de programación JAVA.
Windows Media Audio (WMA)
Ogg Vorbis: es gratuito, abierto y no esta patentado.
Atrac: tecnología de compresión y reproducción para minidisc.
El codec por excelencia: el MP3
Su origen y actualidad
Las siglas MP3 responden a la abreviatura de MPEG
(Moving Picture Expert Group) 1 Layer 3,
que es un algoritmo de codificación perceptual. Este entre otros fue
desarrollado por el Moving Picture Expert Group (MPEG)
(http://www.cselt.it/mpeg/) junto con el Instituto Tecnológico de
Fraunhofer (http://www.ipa.fhg.de/english/).
Moving Picture Expert Group es un comité de investigación del ISO/IEC. El MPEG está a cargo del desarrollo internacional de estándares de compresión, descompresión, procesamiento y la representación codificada de películas, audio y la combinación de ambas. Es una institución sin fines de lucro creada en 1988, que reúne tres veces por año a 300 expertos de 20 países.
Su forma de actuar
Cuando se percibe una señal de un
volumen alto (agudo o de mayor energía) en una frecuencia y otra de
volumen mas bajo (grave o de menor energía) en una frecuencia cercana esta
ultima no será audible. Este efecto se llama enmascaramiento simultaneo o
en frecuencia (también existe el enmascaramiento asimultáneo o en el
tiempo). Y a cierta distancia de la frecuencia enmascaradora, el efecto se
reduce tanto que resulta despreciable. El rango de frecuencias en las que
se produce el fenómeno se denomina banda critica (critical band). La
amplitud de la banda critica varia según la frecuencia en la que nos
situemos y viene dada por determinados datos que demuestran que es mayor
con la frecuencia. De esta manera se trata de desechar todo aquello que el
oído humano no podría captar.
Para aprovechar estas características
se utiliza un sistema denominado Codificación de Sub bandas o CBS
(sub-band coding). Donde el MP3 es el ejemplo más popular. En este proceso
la señal original es descompuesta en sub bandas mediante una base de
filtros. Las sub bandas son comparadas con el original mediante el modelo
psicoacustico que determina que bandas son importantes, cuales no y por
ultimo cuales pueden ser eliminadas.
Del número de bits que utilicemos para producir la codificación depende la eliminación de menor o mayor cantidad de datos siguiendo el modelo psicoacustico hasta lograr la compresión necesaria. Luego se cuantifican y codifican las sub bandas restantes y el resultado es finalmente comprimido mediante un alogaritmo estándar.
Para poder observar mejor todos los conceptos que se introducen de aquí en adelante, se expone a continuación un diagrama de bloques del funcionamiento interno del MP3:
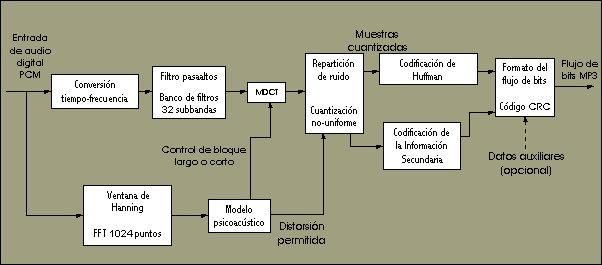
Filtro pasaaltos: proporciona respuesta en frecuencia hasta el nivel de DC (corriente directa ó 0 Hz). Sin embargo, para ciertas aplicaciones, se puede incluir un filtro pasaaltos a la entrada del codificador, con su frecuencia de corte ubicada entre 2 y 10 Hz. La aplicación de tal filtro evita el innecesario requerimiento de una alta tasa de bits para la subbanda más baja y aumenta la calidad total en el sonido.
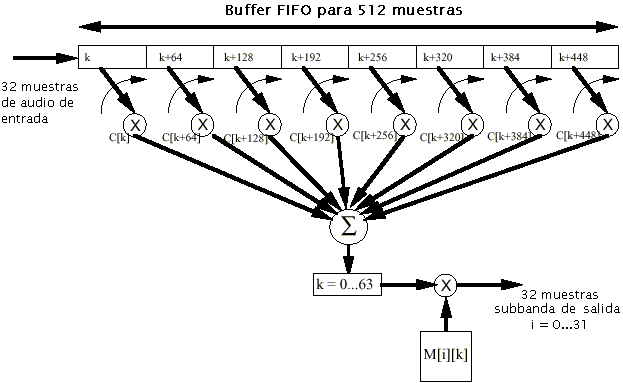
Banco de filtros polifásico: Su función es dividir la señal de audio en 32 subbandas; estas subbandas están igualmente espaciadas en frecuencia, y no reflejan exactamente las bandas críticas del oído.
Transformada discreta del coseno modificada (MDCT).El ancho de banda que proporcionan los filtros es demasiado amplio para las bajas frecuencias, y demasiado estrecho para las altas frecuencias; así que el número de bits del cuantizador no se puede optimizar para la sensitividad al ruido dentro de cada banda crítica. Entonces, lo mejor es que al espectro audible se le hagan particiones en bandas críticas (por medio de la transformada MDCT) que reflejen la selectividad en frecuencia del oído humano.
Analisis psicoacústico
Primero el modelo convierte el audio al dominio espectral, usando una FFT de 1024 puntos para conseguir una buena resolución de frecuencia y poder calcular correctamente los umbrales de enmascaramiento. Antes de la FFT, se aplica una ventana de Hanning convencional para evitar las discontinuidades en los extremos de la señal. La salida de la FFT se usa primero para analizar qué tipo de señal está siendo procesada: una señal estacionaria hace que el modelo escoja bloques largos, y una señal con muchos transitorios da como resultado bloques cortos. El tipo de bloque se usa luego en la parte MDCT del algoritmo. Después de esto, el modelo psicoacústico calcula el mínimo umbral de enmascaramiento para cada subbanda. Estos valores de umbral se usan luego para calcular la distorsión permitida. El modelo pasa entonces las distorsiones permitidas a la sección "REPARTICIóN DE RUIDO" en el codificador para uso posterior.
El estándar proporciona dos modelos psicoacústicos; el modelo I es menos complejo que el modelo psicoacústico II y simplifica mucho los cálculos. Existe considerable libertad en la implementación del modelo psicoacústico; la precisión que se requiera del modelo es dependiente de la aplicación y de la tasa de bits que se quiere lograr. Para bajos niveles de compresión, donde hay un número generoso de bits para realizar la codificación, el modelo psicoacústico puede ser completamente omitido; en cuyo caso, sólo se calcula la relación señal a ruido (SNR) más baja, y con este valor se realiza el proceso de repartición de ruido para la subbanda. A continuación se muestran los pasos generales para el cálculo psicoacústico de la señal.
pasos generales para el cálculo psicoacústico de la señal:
1) Alineación en tiempo. El modelo psicoacústico debe tener en cuenta el retardo de los datos al pasar por el banco de filtros y aplicar un desplazamiento adicional, de tal manera que los datos relevantes queden centrados en la ventana del análisis psicoacústico.
2) Representación espectral. El modelo psicoacústico realiza una conversión del tiempo a la frecuencia para calcular con gran precisión los umbrales de enmascaramiento. usa una transformada de Fourier para realizar el mapeo. Ambos modelos (I y II) procesan los valores espectrales en unidades perceptuales (el bark (100 mel), relacionado con el ancho de las bandas críticas.
3) Componentes tonales y no-tonales. Ambos modelos identifican y separan las componentes tonales y las componentes de ruido en la señal de audio. Esto se debe a que cada componente presenta un tipo de enmascaramiento diferente.
4) Función de dispersión. La capacidad enmascarante de una componente determinada se distribuye por toda la banda crítica que la rodea.
5) Umbral de enmascaramiento individual. Este proceso consiste en escoger únicamente las componentes tonales y no-tonales que verdaderamente enmascaran el sonido (cuya magnitud y distancia en barks debe ser apropiada), desechando el resto de componentes computadas en el paso anterior.
6) Umbral de enmascaramiento global.
Ambos modelos psicoacústicos incluyen un umbral de enmascaramiento absoluto, el cual ha sido determinado empíricamente: el mínimo umbral auditivo en un ambiente silencioso. Se debe recordar que éste es la intensidad del sonido más débil que se puede escuchar cuando no hay más sonidos presentes.
Usando el modelo I, este umbral absoluto se combina con los umbrales individuales calculados en el paso anterior para determinar el umbral de enmascaramiento global sobre toda la banda de audio.
El modelo II no calcula el umbral de enmascaramiento global, sino que trabaja todos los datos dentro de cada subbanda, de acuerdo con el índice de tonalidad que tenga cada componente enmascarante en esa subbanda.
7) Umbral de enmascaramiento mínimo. Ambos modelos psicoacústicos seleccionan el mínimo umbral de enmascaramiento en cada subbanda.
8) Relaciones señal a máscara. Los dos modelos computan la relación señal a máscara, SMR, como la relación entre la energía de la señal en la subbanda y el mínimo umbral de enmascaramiento para esa subbanda.
Cuantificacion:
Tras realizar los dos pasos anteriores por separado (MDCT y análisis psicoacústico) , ahora utilizamos los datos conseguidos en el primer paso y los transformamos mediante otros dos pasos: ciclo interno y externo.
1) Ciclo interno. El ciclo interno realiza la cuantización no-uniforme de acuerdo con el sistema de punto flotante verdadero (cada valor espectral MDCT se eleva a la potencia 3/4). El ciclo escoge un determinado intervalo de cuantización (quantization step size), y a los datos cuantizados se les aplica codificación de Huffman. Si al realizar este proceso se encuentra que el número de bits requerido para codificar los valores excede la cantidad de bits disponibles, de acuerdo con la tasa de bits escogida, entonces el ciclo comienza otra vez con un nuevo intervalo de cuantización, ejecutando la cuantización y la codificación de Huffman otra vez. El ciclo termina cuando los valores cuantizados que han sido codificados con Huffman usan menor o igual número de bits que la máxima cantidad de bits permitida.
2) Ciclo externo. Ahora el ciclo externo se encarga de
verificar si el factor de escala para cada subbanda tiene más distorsión de la
permitida (ruido en la señal codificada), comparando cada banda del factor de
escala (scalefactor band) con los datos previamente calculados en el
análisis psicoacústico. Si cualquiera de las bandas del factor de escala tiene
más ruido que el máximo permitido, el ciclo amplifica esa banda del factor de
escala y ejecuta ambos ciclos (el interno y el externo) de nuevo. El ciclo
externo termina cuando una de las siguientes condiciones se cumple:
Ninguna de las bandas del factor de escala tiene mucho ruido.
La próxima iteración amplificaría una de las bandas más de lo permitido.
Todas las bandas han sido amplificadas al menos una vez.
Ya que el ciclo consume mucho tiempo, una aplicación en tiempo real debe tener en cuenta una cuarta condición, que detenga el ciclo evitando que la codificación se ejecute fuera de tiempo.
NOTA: Codificación de Huffman. Esta técnica crea códigos de longitud variable sobre un número total de bits, donde los símbolos con más alta probabilidad tienen códigos más cortos. Los códigos de Huffman tienen la propiedad de poseer un único prefijo y por lo tanto, pueden ser decodificados correctamente a pesar de su longitud variable; el proceso de la decodificación es muy rápido, a través de una tabla de correspondencias. Este tipo de codificación permite ahorrar, en promedio, aproximadamente un 20% en espacio de almacenamiento.
Las técnicas que se han mostrado son el complemento ideal para la codificación psicoacústica: durante gran polifonía, muchos sonidos están enmascarados o disminuidos, logrando que la codificación psicoacústica sea muy eficiente; y debido a que hay poca información idéntica, entonces el algoritmo de Huffman presenta poca eficiencia. Pero durante los sonidos "puros" hay muy pocos efectos de enmascaramiento, y es aquí donde la codificación de Huffman se vuelve muy eficiente debido a que los sonidos puros, cuando se digitalizan, contienen gran cantidad de bytes redundantes, que entonces serán reemplazados por códigos más cortos.