
En el ámbito general de los códecs (para cualquier tipo de datos), podemos clasificarlos de la siguiente forma, en función si la señal original se puede recuperar o no tras la codificación:
Si nos centramos exclusivamente en audio, en función de la aplicación de cada códec podemos dividirlos en:
También existen códecs que no son específicos para ninguna de estas 2 señales.
Existe otra clasificación de códecs, en función del tipo de algoritmo que se use en la codificación:
A continuación mostramos una gráfica en la que comparamos la calidad de audio ofrecida por cada algoritmo (para señales de voz) en función de la tasa binaria utilizada
Comparación de la calidad ofrecida por cada uno de los algoritmos en función de su tasa binaria. Fuente: [6]
Los códecs de forma de onda persiguen producir una señal reconstruida de la señal a codificar, cuya forma de onda sea lo más parecida a la de dicha señal a codificar. Estos códecs trabajan sin tener conocimiento de cómo la señal a codificar fue generada, lo que implica que en teoría su funcionamiento no depende de la señal y pueden funcionar bien con todo tipo de señales, aunque no sean de audio. En general suelen ser códecs poco complejos. Su principal inconveniente es que para tener una calidad de señal aceptable la tasa binaria ha de ser muy elevada. Este algoritmo es usado para codificar señales de audio de mÚsica, radio, cine, televisión, audio profesional y voz. Para reducir la tasa binaria obtenida con este algoritmo se usa en combinación con otras técnicas como el enmascaramiento, la redundancia entre distintos canales y la codificación predictiva. Una de las formas más usadas para este algoritmo es PCM (Pulse Code Modulation) y también DPCM (Differential Pulse Code Modulation), ya mencionadas anteriormente.
Los códecs de fuente o vocoders operan usando un modelo de cómo se genero la señal de audio en su fuente, e intentan obtener a partir de la señal a codificar, los parámetros del modelo. Estos parámetros son los que se transmiten al decodificador. Los códecs de fuente son llamados vocoders.
A continuación describiremos brevemente como se modela el sistema vocal humano:
La voz se produce cuando el aire se expulsa de los pulmones a través de las cuerdas vocales y a través de la cavidad vocal. Esta cavidad vocal se extiende desde la apertura de las cuerdas vocales (glotis) hasta la boca, y en un hombre suele medir unos 17 cm. Esta cavidad introduce correlaciones a corto plazo (del orden de 1 ms) en la señal de voz. Por lo tanto puede considerarse esta cavidad como un filtro con varias resonancias, que se producen a frecuencias que se varían cambiando la forma de la cavidad (ej. moviendo la lengua). Una parte importante de los códecs para voz es el modelado de la cavidad vocal como un filtro a corto plazo. Como la forma de las cuerdas vocales cambia relativamente despacio, la función de transferencia de este filtro necesita ser actualizada relativamente con muy poca frecuencia (aproximadamente cada 20 ms).
A continuación mostramos un modelo simplificado de la cavidad vocal
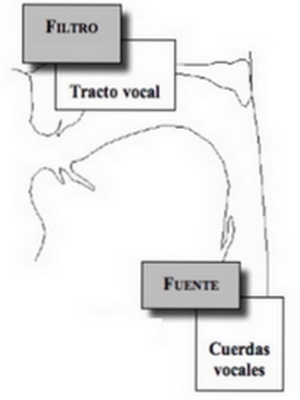
Modelo simplificado de la cavidad vocal humana. Fuente: [7]
Los sonidos de la voz humana pueden dividirse en 3 tipos, dependiendo de la excitación recibida por las cuerdas vocales:


Izquierda:segmento típico de sonido vocal. Derecha:Densidad Espectral de Potencia de un segmento de un sonido vocal. Fuente: [6]


Izquierda:segmento típico de sonido no vocal. Derecha:Densidad Espectral de Potencia de un segmento de un sonido no vocal. Fuente: [6]
Algunos sonidos no se pueden encasillar en ninguna de las 3 clases de sonidos mostrados arriba, ya que son una mezcla de algunos de ellos.
Aunque hay muchos posibles sonidos en la voz humana, la forma de la cavidad vocal y su modo de excitación cambian relativamente despacio, y por lo tanto la voz puede ser considerada como casi-estacionaria en periodos cortos de tiempo, del orden de 20 ms. En las 4 figuras mostradas se ve que la voz humana tiene un alto grado de predecibilidad, debida a veces a las vibraciones casi-periódicas de las cuerdas vocales y también a las resonancias de la cavidad vocal. Los códecs de voz humana aprovechan esta predecibilidad para reducir la tasa de datos necesaria para una transmisión de voz con buena calidad.
De este modo, la generación de un sonido de la voz humana se puede representar de la siguiente manera:

Modelo simplificado de la producción de la voz humana. Fuente: [7]
Una vez visto el modelo simplificado del aparato vocal humano, veamos el funcionamiento de los vocoders
Los códecs de fuente o vocoders operan de la siguiente manera: la cavidad vocal es representada como un filtro que varía con el tiempo y es excitada con una fuente de ruido blanco (para sonidos no vocales) o con un tren de pulsos separados por el periodo del tono (para sonidos vocales). Por lo tanto la información que se manda al decodificador es la especificación de dicho filtro, un señalizador que indique que el sonido es vocal o no vocal, la varianza de la señal original y el periodo del tono para sonidos vocales. Estos parámetros son actualizados cada 10-20 ms para seguir la no estacionariedad de la señal de voz. Los parámetros del modelo pueden ser determinados en el codificador de un nÚmero diferente de formas, usando técnicas en el dominio del tiempo o de la frecuencia. También esta información de los parámetros transmitida puede ser codificada de distintas formas, dependiendo del vocoder en cuestión.
Mostramos a continuación un modelo simplificado de la codificación en un códec de fuente o vocoder
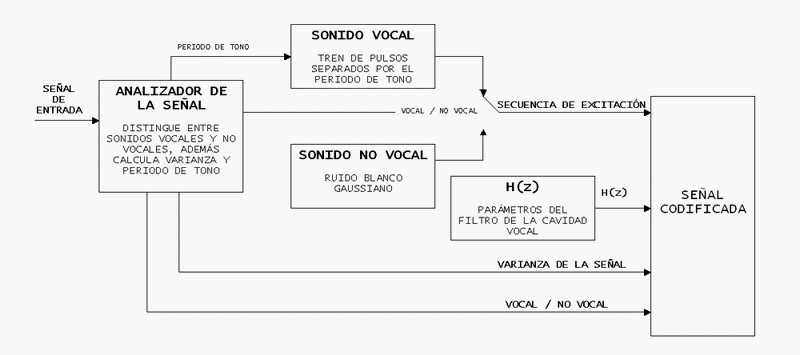
Los vocoders operan a tasas binarias de 2.4Kbps o inferiores y producen señales de voz que aunque inteligibles para nosotros, nos suenan demasiado sintéticas. Aumentar la tasa binaria para obtener mayor calidad no es posible debido a que así no aumenta el rendimiento del códec, ya que el modelo que se asume para la señal de voz de la fuente es muy simple. Se usan mayoritariamente en aplicaciones militares, donde que la voz suene sintética no es un gran problema, ya que lo más importante en este caso es tener una tasa binaria muy baja para permitir fuertes técnicas de encriptación y protección, que añadirán gran redundancia a la señal transmitida.
Este tipo de códecs son una mezcla entre los de forma de onda y los de fuente. Dentro de los códecs híbridos, los más utilizados son los códecs en el dominio del tiempo de Análisis-por-Síntesis (Análisis-by-synthesis) (AbS). Estos códecs usan el mismo modelo de filtro de predicción lineal para la cavidad vocal que los vocoders. Pero en lugar de aplicar solamente dos estados (sonido vocal/sonido no vocal) para el modelo de señal de exicitación del filtro, se usa otro modelo de señal de excitación. Este nuevo modelo se escoje para intentar que la forma de onda de la señal una vez decodificada sea lo mas parecida a la de la señal original. Los códecs de Análisis-por-Síntesis fueron introducidos por primera vez en 1982 por Atal y Remde, conocidos como MPE (Multi-Pulse-Excited). Más adelante los códecs RPE (Regular Pulse Excited) y CELP (Code-Excited Linear Predictive) fueron introducidos.
A continuación se muestra un esquema general para el codificador y el decodificador de un códec AbS

Esquema simplificado del codificador de un códec híbrido. Fuente: [6]
Los códecs AbS funcionan separando la señal de entrada de audio en tramas, de unos 20 ms de duración. Para cada trama los parámetros de ésta son determinados por un filtro de síntesis, y después la excitación a este filtro es determinada, encontrando la señal de excitación que cuando pasa por el filtro dado de síntesis minimice el error entre la señal de entrada original y la señal reconstruida. De esto viene el nombre de Análisis-por-Síntesis, ya que el codificador analiza la señal de entrada sintetizando varias aproximaciones a ella. Por último, para cada trama el codificador transmite la información que representa los parámetros del filtro y la excitación a éste. El decodificador con éstos parámetros, lo que hace (a grandes rasgos) es tomar la señal de excitación para el filtro que ha recibido y pasarla por el filtro de síntesis para obtener la señal de voz decodificada. El filtro de síntesis es habitualmente un filtro de todo-polos, a corto plazo y lineal, de la forma:
 donde
donde

es el filtro de predicción del error determinado minimizando la energía de la señal residual producida cuando el segmento elegido de voz pasa a través de él. El orden p del fltro suele ser alrededor de 10. Este filtro está destinado a modelar las correlaciones introducidas en la señal de voz por la acción de la cavidad vocal.
Este filtro de síntesis puede también incluir un filtro de tono para modelar las periodicidades a largo plazo que aparecen en los sonidos vocales. Alternativamente estas periodicidades a largo plazo pueden aprovecharse incluyendo un codebook adaptativo en el generador de la excitación, de tal forma que la señal de excitación incluya una componente de la forma Gu(n-a), donde a es el periodo estimado para el tono. Generalmente los codecs MPE y RPR funcionan sin filtro de tono, aunque su rendimiento se mejora si se les incluye uno. Para los códecs CELP el filtro de tono es extremadamente importante.
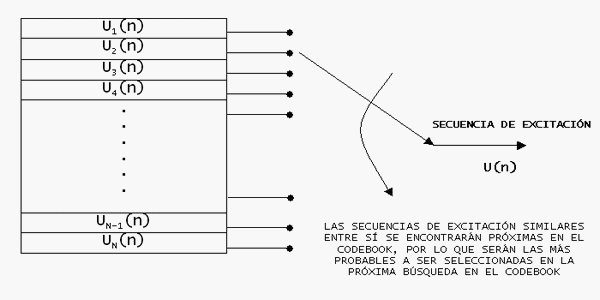
Para dejar un poco más claro el concepto del codebook que aparece en estos códecs veamoslo de la siguiente manera:
El codebook es como un diccionario de sonidos. Estas pequeñas partes de sonidos que van llegando en tramas al codificador se podrían intepretar como micro-fonemas. Cuando le enviamos un trozo de voz al códec, este lo reemplaza con una referencia a una palabra de su diccionario (el codebook) y lo envía. También prepara los siguientes sonidos que cree que pueden precederle (predicción a corto y largo plazo). Así es cómo el códec comprime la voz tan bien. Realmente estos códecs no envían absolutamente nada de la voz original, envían trozos matemáticos que han ido creando en tiempo real. Por este motivo, la voz se escucha perféctamente, mientras otras señales como por ejemplo la música no.
El bloque de pesado del error (error weighting) se usa para modelar el espectro de la señal de error, para reducir el loudness subjetivo de ese error. Esto es posible porque la señal de error en las regiones de frecuencia donde la voz tiene alta energía, la señal de error será parcialmente enmascarada por la voz. El filtro de pesado del error (error weigthing) enfatiza el ruido en las zonas de frecuencia donde el contenido de voz es bajo. De este modo, minimizar el peso del error concentra la energía del error en zonas de frecuencia donde la voz tiene alta energía. Por lo tanto la señal de error será parcialmente enmascarada por la de voz, y su importancia subjetiva se verá reducida. Este pesado se dice que produce una mejora significativa en la cualidad subjetiva de la voz reconstruida por códecs AbS.
La característica que distingue a los códecs AbS es como la forma de onda de la excitación u(n) es elegida. Conceptualmente cualquier forma de onda posible se pasa a través del filtro para ver qué señal de voz reconstruida produciría. La excitación que de el mínimo error de peso entre la señal original y la señal reconstruida es entonces escogida por el codificador y usada para construir el filtro de síntesis en el decodificador. Es esta determinación en bucle cerrado la que permite a estos codecs dar tan buena calidad a tan bajas tasas binarias. Pero por el contrario la complejidad numérica relacionada con pasar cada posible señal de excitación a través del filtro de síntesis es enorme. Habitualmente algunas formas de reducir esta complejidad, sin comprometer el rendimiento del códec demasiado, deben ser encontradas.
La diferencia entre MPE, RPE y CELP surge en la representación de la señal de excitación u(n) utilizada. En MPE u(n) viene dada por un número fijo de pulsos no nulos para cada trama de voz. Las posiciones de esos pulsos no nulos dentro de la trama, y sus amplitudes deben ser determinadas por el codificador y transmitidas al decodificador. En teoría sería posible encontrar los mejores para todas las posiciones de pulsos y amplitudes, pero no se hace en la práctica debido a la excesiva complejidad que esto conllevaría. En la práctica se usan algunos métodos sub-óptimos para encontrar las posiciones y amplitudes de los pulsos. Típicamente, sobre 4 pulsos cada 5 ms son usados, y esto lleva a una buena calidad de la señal reconstruida a unos 10Kbps
RPE también usa un número de pulsos no nulos para dar la señal de excitación u(n). Pero al contrario que en MPE, en RPE los pulsos están regularmente espaciados en algÚn intervalo fijo, y el codificador sólo necesita determinar la amplitud del 1er pulso y la amplitud de todos ellos. De este modo se transmite menos información sobre posiciones de pulsos, y para una tasa dada de RPE, puede usar un número mayor de pulsos no nulos que MPE. Por ejemplo, a una tasa binaria de 10Kbps unos 10 pulsos cada 5 ms pueden ser usados en RPE, frente a los 4 de MPE. Esto permite a los códecs con algoritmo RPE dar una ligera mejor calidad de la señal reconstruida que los MPE.
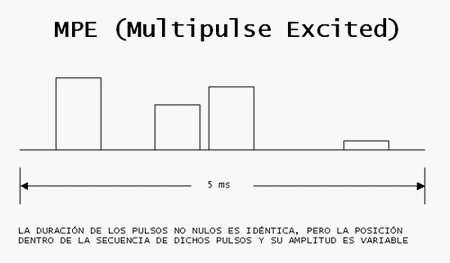
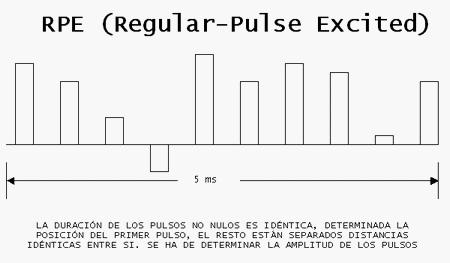
Aunque los códecs MPE y RPE pueden dar buena calidad a tasas de unos 10kbps y mayores, no son adecuados para tasas binarias muy por debajo de éstas. Esto es debido a la gran cantidad de información que ha de ser transmitida sobre las posiciones y amplitudes de los pulsos que representan la señal de excitación u(n). Si se intenta reducir la tasa binaria usando menos pulsos y cuantificando de manera poco precisa sus amplitudes, la calidad de la señal reconstruida disminuye drásticamente.
En la actualidad el algoritmo más usado para producir una señal reconstruida de voz de buena calidad a tasas menores de 10 kbps es CELP (Code Excited Linear Prediction). Esta aproximación fue propuesta por Schroeder y Atal en 1985 y su diferencia con MPE y RPE es que la señal de excitación u(n) está cuantificada vectorialmente de manera efectiva. La excitación viene dada por una posición de un gran codebook de vectores cuantificados, y por un término de ganancia para controlar la potencia de la señal. Típicamente las posiciones de los vectores del codebook se representan con 10 bits (para tener 1024 posiciones en el codebook) y la ganancia con 5 bits. De este modo la tasa binaria para transmitir la información sobre la señal de excitación disminuye considerablemente (15 bits comparados con los 47 usados en el códec que se usa en el sistema GSM (que usa RPE).
Originalmente el codebook usado en los códecs CELP contenía secuencias blancas gaussianas. Esto era debido porque se asumía que los predictores a corto y largo plazo erían capaces de eliminar casi toda la redundancia de la señal de voz para producir una señal residual parecida a ruido. También se demostraba que la función de densidad de probabilidad de esta señal residual era muy parecida a una gaussiana. Schroeder y Atal encontraron que usando tal codebook para producir la excitación para filtros de síntesis a corto y largo plazo podrían producir una señal de alta calidad. Por el contrario, elegir qué posición del codebook tenía que utilizarse significaba que todas las secuencias de excitación tenían que pasar a través de los filtros de síntesis para ver como de fiel era la señal reconstruida a la original. Esto impuso que la complejidad del códec CELP era demasiado elevada para ser implementada en tiempo real (llevó 125 segundos a un ordenador Cray procesar un segundo de la señal de voz). Desde 1985 se ha trabajado mucho en reducir la complejidad de estos códecs, principalmente alterando la estructura del codebook. También se han conseguido grandes avances en la velocidad de procesamiento de los DSPs, de tal forma que en la actualidad es relativamente sencillo implementar un códec CELP en tiempo real en un solo DSP de bajo coste. Bastantes estándares de codificación de voz se han definido basándose en CELP, por ejemplo el G.728, G.729 e iLBC.
El principio de codificación de CELP ha tenido mucho éxito para producir comunicaciones a calidad de telefonía estándar con tasas binarias entre 4.8 y 16 kbps. Los estándares de la ITU-T a 16kbps producen una señal de voz que es casi indistinguible de PCM con ley A a 64kbps. Recientemente se trabajado mucho en códecs que operen por debajo de los 4.8 kbps, con el objetivo de producir un códec a 2.4 o 3.6 kbps, con calidad de voz equivalente aceptable, con el objetivo de que la voz sea algo más inteligible. Daremos brevemente algunas aproximaciones que se siguen prometiendo en la busca de tal códec.
La estructura de los códecs CELP puede mejorarse y ser usados a tasas binarias menores de 4.8 kbps clasificando segmentos de voz en un número de tipos (ej, sonidos vocales, no vocales y tramas de transición entre ambos tipos de sonidos). Los diferentes tipos de segmentos de voz son entonces codificados con un codificador diferente para cada uno. Por ejemplo, para tramas sin sonidos vocales, el codificador no usará ningÚn tipo de prediccón a largo plazo, mientras que para tramas con sonidos vocales esta predicción es vital, pero el codebook fijo puede ser menos imporante. Estos códecs que codifican según el tipo de sonido han sido capaces de producir señales vocales de calidad razonable a tasas menores que 2.4 kbps. Los códecs de excitación multi-banda (MBE) funcionan declarando algunas zonas del dominio de la frecuencia como vocales y otras como no vocales. Se transmite para cada trama información del periodo del tono, la magnitud espectral, la fase y decisiones para los armónicos de la frecuencia fundamental. Originalmente se demostró que dicha estructura era capaz de producir voz de buena calidad a 8kbps, y desde entonces esta tasas ha sido reducida significativamente. Por último, Kleijn ha suerido una propuesta para codificar segmentos de voz con sonidos vocales llamada PWI. Funciona mandando información sobre un solo ciclo del tono cada 20-30 ms, y usando interpolación para reproducir una forma de onda casi-periódica con ligeras variaciones para segmentos de voz con sonidos vocales. Con este método se puede obtener una excelente calidad para tasas binarias tan bajas como 3kbps. Este tipo de códec puede combinarse con un CELP para los segmentos de voz de sonidos no vocales para dar buena cualidad de voz a tasas por debajo de 4 kbps.